Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models
Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, Lingming Zhang · 2023년 · ISSTA 2023
관련도: 상 · 읽은 이유: LLM Fuzzing(Universal Fuzzing) 학습
딥러닝 라이브러리를 테스트하기 위해 수동으로 문법 규칙을 정의하는 대신, 수천만 개의 오픈소스 코드를 학습한 대규모 언어 모델의 내부 지식을 활용하면 복잡한 API 제약 조건과 시퀀스를 만족하는 입력 프로그램을 제로샷으로 자동 생성 및 변이할 수 있다.
One-liner
대규모 언어 모델의 코드 생성 및 인필링 기능을 진화 알고리즘 및 다중 무장 강도 기반의 연산자 선택 전략과 결합하여 딥러닝 라이브러리의 코드 커버리지를 극대화하고 숨은 버그를 탐지하는 자동화 퍼징 프레임워크를 제안한다.
Problem
TensorFlow나 PyTorch 같은 딥러닝 라이브러리는 엄격한 프로그래밍 언어의 구문뿐만 아니라, 텐서 차원 및 입력 데이터 타입 제약 조건을 동시에 만족해야 하므로 전통적인 퍼징 기법을 적용하기 매우 어렵다. 기존의 모델 기반 퍼저는 변이 규칙이 지나치게 제한적이거나 수동 주석이 필요하여 소수의 API만 커버할 수 있었고, API 기반 퍼저는 단일 API를 고립된 환경에서만 테스트하여 여러 API가 체인 형태로 연결되었을 때 발생하는 버그를 탐지하지 못하는 한계가 존재한다.
Core Idea
현대의 대규모 언어 모델은 텐서 계산과 관련된 수많은 딥러닝 API 호출 코드가 포함된 방대한 코퍼스로 학습되었기 때문에, 파이썬 구문 규칙과 복잡한 딥러닝 API 제약 조건을 이미 암묵적으로 학습하고 있다. 이를 활용하면 별도의 미세조정 과정 없이 프롬프트 엔지니어링과 인필링 모델을 통해 유효하고 실용적인 테스트용 딥러닝 프로그램을 직접 생성하고 변이할 수 있다.
Method
TitanFuzz의 전체 아키텍처는 초기 시드 프로그램 생성 단계와 이를 확장하는 진화형 퍼징 루프로 구성된다.
1. 초기 시드 생성
대상 라이브러리와 HTML 크롤러로 자동 추출한 API 시그니처 정보를 바탕으로 단계별 명령어 프롬프트를 구성한다. 이를 생성형 모델인 Codex에 입력하여 문법적으로 유효한 기본 시드 코드를 제로샷으로 샘플링한다.
2. 변이 연산자 및 인필링
코드의 특정 위치를 <SPAN> 토큰으로 대체한 후 인필링 모델인 INCODER를 통해 주변 문맥에 맞는 코드를 채워 넣는 방식으로 변이를 수행한다. 변이 연산자는 다음 네 가지 유형을 사용한다.
- Argument: API 호출 인자를 바꾸거나, 대입 연산자를 사이에 둔 두 개의 span 토큰을 배치하여 모델이 새로운 키워드 인자를 삽입하도록 유도한다.
- Prefix: API 호출 이전 라인들을 변이하여 데이터 생성 방식을 다각화한다.
- Suffix: API 호출 이후 라인에 span 토큰을 두어 모델이 연속적인 차후 API 시퀀스를 추가 생성하도록 만든다.
- Method: 유효한 입력 구조를 유지한 채 관계형 API의 이름만 변경하여 결함을 유도한다.
3. Thompson Sampling 기반 연산자 선택
각 API마다 효율적인 변이 연산자가 다르다는 점에 착안하여 연산자 선택 문제를 베르누이 다중 무장 강도 모델로 정의한다. 톰슨 샘플링 알고리즘을 통해 사후 분포를 업데이트하며 유효 변이 생성 확률이 높은 연산자를 동적으로 우선 선택한다. 베타 분포의 초기 belief 파라미터는 , 로 설정하여 균등 분포로 시작한다.
4. 적합도 함수
장황하고 단순 반복되는 코드를 배제하고 복잡한 API 상호작용을 유도하기 위해 다음과 같은 적합도 함수를 정의하여 시드 은행 내 우선순위를 관리한다.
여기서 는 정적 분석으로 파악한 데이터 흐름 그래프의 최대 깊이, 는 고유한 라이브러리 API 호출 횟수이며, 은 동일한 입력으로 중복 호출된 API 횟수에 대한 감점 항목이다.
5. 차등 실행 및 오라클
생성된 프로그램을 CPU와 GPU 백엔드에서 각각 실행하는 차등 테스트를 수행한다. 허용 오차 임계값을 넘어서는 계산 값 차이가 발생하는 경우와 세그멘테이션 결함 등 예외 처리가 되지 않는 비정상 종료를 감지하여 버그를 판정한다.
Results
TensorFlow v2.10 및 PyTorch v1.12 환경에서 기존 최첨단 퍼저들과 비교 평가를 진행했다.
API 및 코드 커버리지 성능
- API 커버리지: TensorFlow에서 2215개, PyTorch에서 1329개의 API를 커버하여 최우수 기본 모델인 DeepREL 대비 각각 91.11%, 24.09% 향상된 최고 성능을 기록했다.
- 라인 커버리지: PyTorch에서 20.98%, TensorFlow에서 39.97%의 라인 커버리지를 달성하여 DeepREL 대비 각각 50.84%, 30.38%의 향상을 보였다. 기존 도구들이 10-20초 이후 커버리지 포화 상태에 이르는 반면, TitanFuzz는 50초 이후에도 지속적으로 새로운 코드 경로를 발굴했다.
버그 탐지 결과
- 총 65개의 버그를 탐지하였으며, 개발자 검증을 거쳐 최종적으로 55개 버그 확정, 그중 44개가 이전에 발견된 적 없는 고유한 신규 버그로 인정되었고 21개 버그에 대한 패치가 완료되었다. 탐지된 결함 중에는 CPU와 GPU 간의 NaN 처리 불일치 및 out-of-bound read 현상을 유발하는 보안 취약점이 포함되어 있었다.
Key Figures
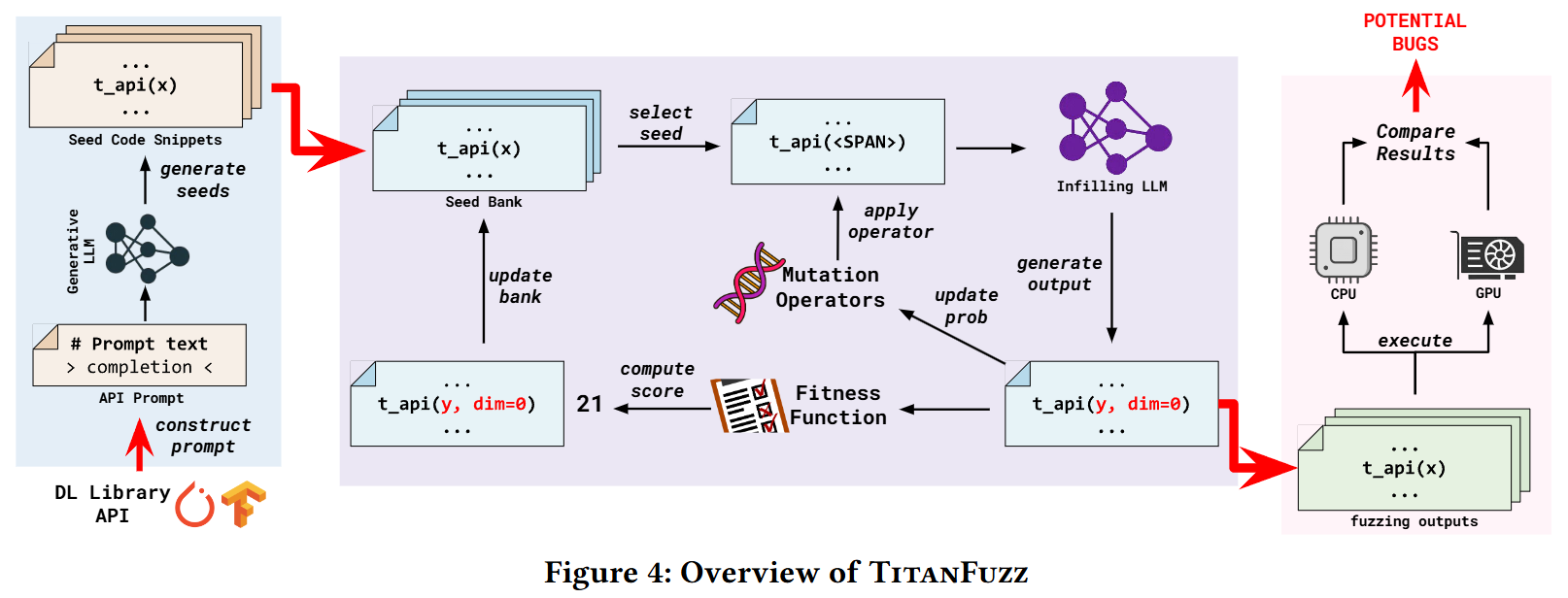
- Fig. 4: 초기 시드 생성 단계부터 연산자 변이, INCODER 인필링, 적합도 평가 기반 피드백 루프, 그리고 CPU/GPU 차등 실행 오라클로 이어지는 TitanFuzz의 전체 흐름도 메커니즘을 시각화한다.

- Fig. 6: 소스 코드의 인자, 접두사, 접미사, 메서드 영역에 각각
<SPAN>마커를 배치하여 인필링 모델의 입력 형태로 변환하는 네 가지 변이 유형의 실제 예시를 제시한다.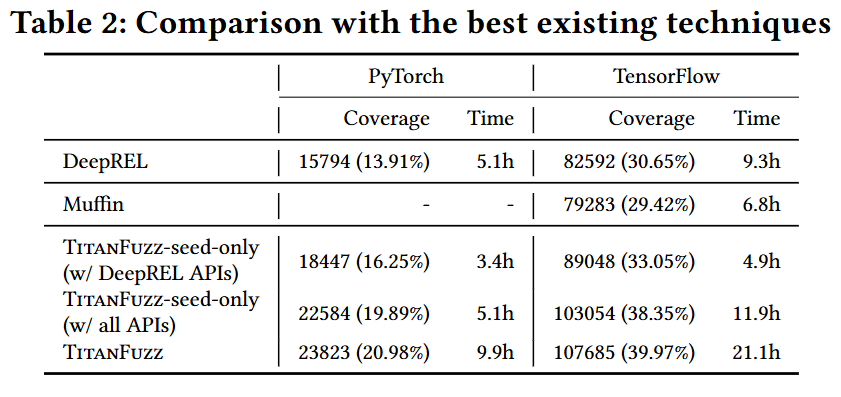
- Table 2: 최첨단 API 수준 퍼저인 DeepREL 및 모델 수준 퍼저 Muffin과의 라인 커버리지 및 실행 시간을 대조한 표로, 시드만 사용한 변종도 기존 기법의 성능을 압도함을 보여준다.
Contribution vs Limitation
저자 주장
- 대규모 언어 모델을 퍼징 엔진으로 직접 활용하는 새로운 차원의 연구 방향성을 제시했다.
- 별도의 미세조정 과정 없이 프롬프트 엔지니어링만으로 엔드투엔드 입력 프로그램 생성이 가능함을 증명했다.
- 양방향 문맥을 활용하는 인필링 모델을 진화 알고리즘의 변이 기법에 최초로 도입했다.
저자가 밝힌 한계
- 차등 테스트 수행 시 특정 연산의 비결정론적 특성으로 인해 발생하는 미세한 값 차이를 다루기 위해 휴리스틱 오차 임계값에 의존해야 하므로 오탐 가능성이 존재한다.
- 하드웨어 제조사 사양이나 하위 수준 구현 차이로 인해 발생하는 모호한 예외는 개발자에 의해 버그가 아닌 구현 정의 사항으로 거부될 수 있다.
Quotes
"To address these limitations, we propose TITANFUZZ - the first approach to directly leveraging Large Language Models (LLMs) to generate input programs for fuzzing DL libraries." (p.1)
"Our key insight is that modern LLMs can also include numerous code snippets invoking DL library APIs in their training corpora, and thus can implicitly learn both language syntax/semantics and intricate DL API constraints for valid DL program generation." (p.1)
"To our knowledge, this is also the first work demonstrating that modern titanic LLMs can directly perform both generation-based and mutation-based fuzzing studied for decades..." (p.2)
Idea Seeds
- 도메인 확장: 웹 어셈블리 컴파일러, 그래프 데이터베이스 질의 엔진, 또는 가상화 하이퍼바이저 등 입력 포맷이 정교하고 구문 제약 조건이 빽빽한 다른 시스템 소프트웨어 도메인으로 본 기법의 프롬프트 구성 방식을 확장 적용한다.
- 로컬 경량화: 외부 API 의존성을 탈피하기 위해 인필링에 특화된 최신 오픈소스 소형 코드 모델을 로컬 환경에 배치하여 추론 병목을 제거하고 고속 퍼징 루프를 구축한다.
For My Writing
- 인용 지점: 딥러닝 컴파일러 및 라이브러리 테스트 관련 연구를 정리하는 논문의 서론이나 관련 연구 섹션에서, 수동 규칙 기반 문법 생성의 한계를 대규모 언어 모델의 생성 지식으로 돌파한 최초의 연구 사례로 이 논문을 인용한다.
- 비교 분석: 생성형 모델과 인필링 모델의 역할을 분담하여 시드 생성과 프로그램 변이를 이원화하는 파이프라인의 타당성을 논증하는 기초 근거 자료로 활용한다.
Open Questions
이해하지 못한 것
- 톰슨 샘플링 기반의 다중 무장 강도 알고리즘이 가동될 때 각 API 단위로 독립된 게임이 수행되는데, 초기 파라미터 환경에서 급격히 특정 연산자로 쏠리는 조기 수렴 현상이나 차가운 시작 문제를 방지하기 위해 정교하게 설계된 보상 스케일링 기법이 구체적으로 어떻게 세팅되었는지 명확하지 않다.
저자가 다루지 않은 것
- 모델이 무효한 문법 코드를 뱉어낼 때 마지막 줄을 단순 삭제하는 사후 처리 방식 외에, 대규모 언어 모델의 디코딩 시점에 타깃 언어의 문법 구조를 강제하는 문법 제약 조건 디코딩 알고리즘을 결합했을 때의 퍼징 효율성 및 유효 프로그램 생성율 변화에 대해서는 다루지 않았다.
Links
- 선행 연구: FreeFuzz(오픈소스 마이닝 기반 API 퍼저), DeepREL(관계형 API 추론 기반 테스트), INCODER(코드 인필링 벤치마크 모델)
- 관련 주제: CODAMOSA(사전 학습 모델 기반 탐색 소프트웨어 테스트), TestPilot(대규모 언어 모델 활용 단위 테스트 자동 생성)
References
- DOI: 10.1145/3597926.3598067
- arXiv: 2212.14834
- Code: github.com/ise-uiuc/TitanFuzz
- BibTeX key:
deng2023large
@inproceedings{deng2023large,
title = {Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models},
author = {Deng, Yinlin and Xia, Chunqiu Steven and Peng, Haoran and Yang, Chenyuan and Zhang, Lingming},
booktitle = {Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis},
pages = {423--435},
year = {2023},
publisher = {ACM}
}