Do Neural Language Models Overcome Reporting Bias?
Vered Shwartz, Yejin Choi · 2020 · COLING 2020
관련도: 상 · 읽은 이유: 내 논문에 인용하기 위해서, 보고 편향을 역으로 이용해 Edge case로 활용
신문 기사만 읽고 세상을 배운 AI는 사람들이 숨을 쉬는 횟수보다 살인 사건이 일어나는 횟수가 더 많다고 믿는다. 언어 모델은 일반화 능력으로 '당연한 사실'을 추측해내기도 하지만, 코퍼스에 기록된 '자극적인 예외'에 더 강하게 반응하는 경향이 있다.
One-liner
신경망 언어 모델은 텍스트 코퍼스의 통계적 왜곡인 Reporting Bias (보고 편향)를 완전히 극복하지 못하며, 오히려 드문 사건의 가능성을 실제보다 높게 측정하여 편향을 증폭시킨다.
Problem
인간의 대화에는 Grice's maxim of quantity (그라이스의 양의 격률)가 작용하여, 너무 당연한 사실(사람은 숨을 쉰다)은 생략되고 드물거나 주목할 만한 사건(사람이 살해당했다)은 과도하게 기록된다. 이를 Reporting Bias (보고 편향)라고 한다. 기존의 추출적 지식 획득 방식은 이 편향에 취약했는데, 최근의 거대 언어 모델(LLM)이 가진 일반화 능력이 이 문제를 해결할 수 있는지 검증이 필요하다.
Core Idea
거대 언어 모델이 코퍼스에 명시적으로 나타나지 않는 '당연한 상식'을 얼마나 잘 복원하는지, 그리고 '자극적인 사건'에 대한 빈도를 어떻게 평가하는지 실제 세계의 통계와 비교 분석한다. 이를 위해 Actions/Events, Event Outcomes, Properties 세 가지 측면에서 실험별로 적합한 모델을 선택하여 평가한다.
Method
- Action Frequency Comparison: 실제 세계의 행동 빈도(CDC 평균 수명 통계 등 미국 공공 통계 자료), Google N-grams 빈도, 그리고 LMs(BERT, RoBERTa, GPT-2)의 문장 완성 점수를 비교한다.
- Event Outcome Analysis: COPA (Choice of Plausible Alternatives) 데이터셋을 활용하여 원인과 결과에 대한 제로샷 예측 성능을 측정한다. 이 실험에서는 생성형 모델인 GPT, GPT-2, XLNet을 사용한다.
- Property Prediction: 사물의 색상(예: 바나나-노란색)을 예측하게 하여, 모델(BERT, RoBERTa)이 개념과 속성을 올바르게 연결하는지 확인한다.
- Zero-shot+DE Model: Disconfirmed Expectations (기대 위반) 패턴(예: "...했지만 다치지 않았다")을 활용하여 모델이 일반적인 결과를 더 잘 예측하는지 실험한다.
Results
- 편향의 증폭: KL-Divergence 측정 결과, LMs의 점수 분포가 Google N-grams보다 실제 세계의 빈도 분포에서 더 멀리 떨어져 있었다. 특히 '살인'이나 '체포' 같은 희귀 사건의 점수를 코퍼스 빈도보다도 높게 책정했다.
- 학습 데이터의 영향: BERT는 위키백과와 BooksCorpus로 학습되어 역사적 인물 항목의 영향으로 '죽음'에 대한 점수가 매우 높았고, 웹 데이터를 학습한 RoBERTa는 뉴스 가치가 있는 자극적인 사건에 더 민감했다.
- 부정어에 대한 취약성: 기대 위반(DE) 패턴을 추가했을 때 성능이 오히려 하락했는데, 이는 LMs가 부정어(negation)를 제대로 처리하지 못하고 단순한 어휘 연관성에 의존하기 때문이다.
- 과잉 일반화: 색상 예측 시 '초록색'과 '노란색'처럼 의미적으로는 유사하지만 상호 배타적인 속성을 혼동하는 경향을 보였다.
| 모델/데이터 | KL-Divergence (실제 분포와의 차이) | 특징 |
|---|---|---|
| Google Ngrams | 2.94 | 당연한 사실은 거의 0에 수렴 |
| BERT | 3.77 | 위키백과 인물 데이터 영향으로 '죽음' 과대평가 |
| GPT-2 | 3.77 | BERT와 동일 수준으로 실제 분포에서 괴리 |
| RoBERTa | 3.08 | 뉴스 및 웹 데이터 영향으로 자극적 사건 선호 |
Key Figures
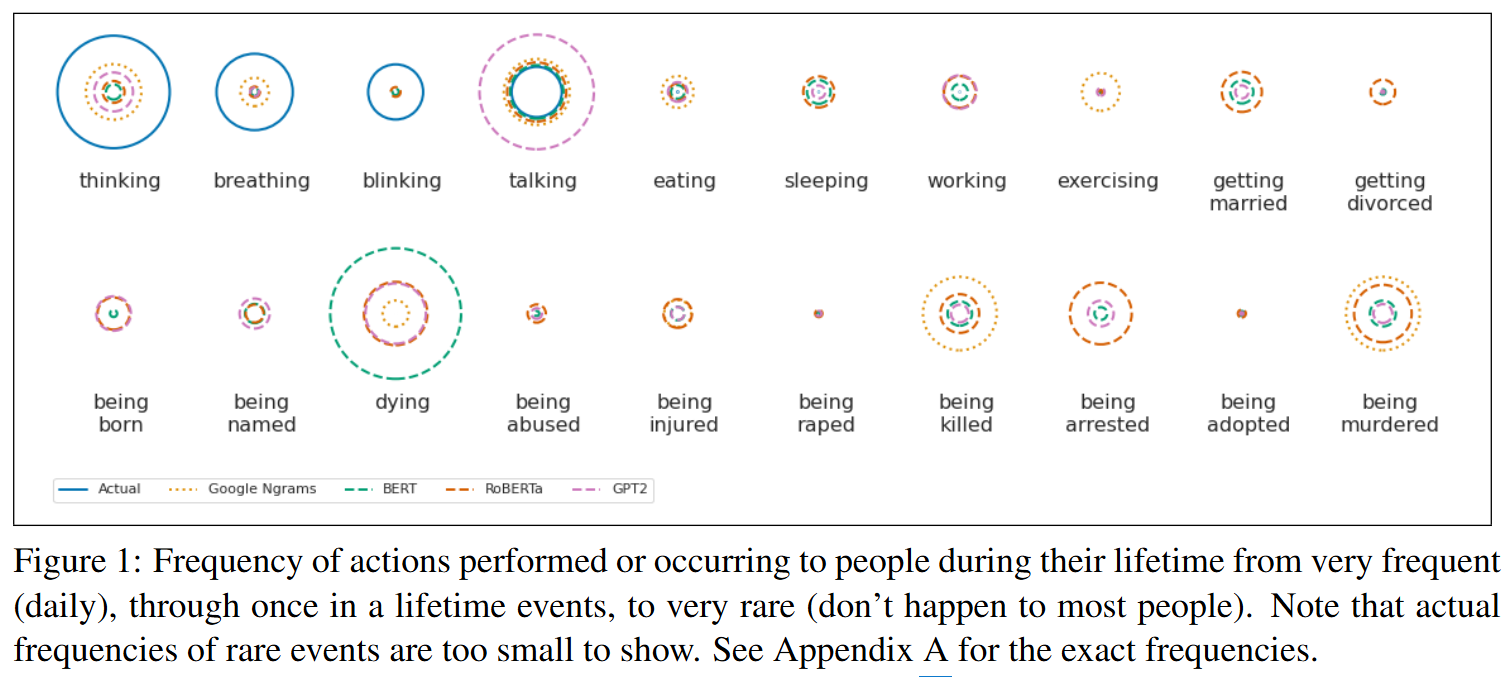
- Fig. 1: 행동 빈도 시각화. 실제 세계에서는 '숨쉬기', '생각하기'가 압도적이지만, 모델들은 '살인', '결혼' 등에 더 높은 상대적 점수를 부여한다.

- Table 2: 생성된 결과 예시. "수도꼭지를 틀었다"는 입력에 대해 "물이 나온다"는 평범한 결과와 "불이 났다", "피가 튀었다"는 자극적 결과가 공존한다.
Contribution vs Limitation
저자 주장
- LMs가 코퍼스에 없는 사소한 사실에 대해 비제로(non-zero) 점수를 부여함으로써 어느 정도 일반화 능력을 갖췄음을 증명했다.
- 하지만 보고 편향을 극복하기는커녕 드문 사건을 과대평가하여 편향을 강화하고 있음을 확인했다.
저자가 밝힌 한계
- LM의 점수는 엄밀한 의미의 빈도나 확률이 아니라 '개연성(plausibility)'의 대리 지표로 사용되었다.
- 실제 빈도 데이터가 미국 공공 통계에 기반하고 있어 문화적 다양성을 반영하지 못한다.
- 이 논문은 LLM이 '상식'을 가지고 있다고 믿는 것이 위험할 수 있음을 정량적으로 보여준다.
- 특히 뉴스 가치가 높은 데이터를 주로 학습하는 구조상, 모델이 생성하는 결과가 편향된 현실을 더 극대화하여 보여줄 위험이 있음을 시사한다.
Quotes
"Mining commonsense knowledge from corpora suffers from reporting bias, over-representing the rare at the expense of the trivial." (p.1) "LMs also exaggerate the frequencies of rare events (e.g. dying), producing estimates not only higher than the actual frequency but even higher than the corpus frequency." (p.2) "LMs, compared to extractive methods: Provide a worse estimate of action frequency, mostly due to overestimating very rare actions." (p.1)
Idea Seeds
- News-Filtered Training: 학습 데이터에서 뉴스 기사의 비중을 조절하거나, '평범한 일기' 데이터의 비중을 높였을 때 보고 편향이 얼마나 완화되는지 실험할 수 있다.
- Multimodal Grounding: 시각 데이터(이미지/영상)에는 '숨쉬기' 같은 행위가 배경으로 깔리는 경우가 많으므로, 텍스트와 이미지를 함께 학습하는 것이 보고 편향 극복의 열쇠가 될 수 있다.
For My Writing
이 논문은 언어 모델의 신뢰성이나 상식 추론 능력을 다루는 섹션에서 Reporting Bias (보고 편향)의 증거로 인용하기 적합하다. 특히 "단순히 데이터 양을 늘리는 것이 편향 해결의 정답이 아님"을 강조할 때 BERT와 RoBERTa의 사례를 사용할 수 있다.
Open Questions
이해하지 못한 것
- LM 점수를 정규화하는 과정에서 소프트맥스 온도(temperature) 설정이 결과의 편향 정도에 어떤 영향을 미치는지 명확히 설명되지 않았다.
저자가 다루지 않은 것
- 모델의 크기(parameter size)가 커질수록 이 보고 편향이 심화되는지, 아니면 오히려 완화되는지에 대한 스케일링 법칙 연구가 빠져 있다.
Links
- 선행 연구: Gordon and Van Durme (2013) - 보고 편향의 개념을 처음 제안한 연구
- 관련 주제: Hallucination (환각), Social Bias in NLP (NLP에서의 사회적 편향)
References
- ACL Anthology: 2020.coling-main.605
- DOI: 10.18653/v1/2020.coling-main.605
- Code: github.com/vered1986/reporting_bias_lms
- BibTeX key:
shwartz2020reporting
@inproceedings{shwartz2020reporting,
title = {Do Neural Language Models Overcome Reporting Bias?},
author = {Shwartz, Vered and Choi, Yejin},
booktitle = {Proceedings of the 28th International Conference on Computational Linguistics},
pages = {6863--6870},
year = {2020},
publisher = {International Committee on Computational Linguistics}
}