FUZZ4ALL: Universal Fuzzing with Large Language Models
Chunqiu Steven Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, Lingming Zhang · 2024 · International Conference on Software Engineering
관련도: 상 · 읽은 이유: LLM Fuzzing(Universal Fuzzing) 학습
문법 규칙과 제약 조건을 수만 줄의 코드로 직접 하드코딩하는 대신, 이미 방대한 소스코드를 사전 학습한 대규모 언어 모델에게 타깃 명세서만 요약해 쥐어주면 모델 스스로 문법과 명세를 이해하고 똑똑하게 입력 변이를 수행하며 버그를 찾아낼 수 있다.
One-liner
대규모 언어 모델의 다국어 코드 이해 능력을 활용하고 자동 프롬프트 정제 및 진화 메커니즘을 설계하여, 특정 언어에 종속되지 않고 다양한 프로그래밍 언어 환경에서 동작하는 최초의 범용 퍼징 프레임워크다.
Problem
컴파일러, 런타임 엔진, 제약 솔버 등 복잡한 정형 언어를 입력으로 받는 시스템을 테스트하는 기존 퍼저들은 특정 입력 언어나 특정 버전에 강하게 결합되어 있다. 이로 인해 새로운 언어로 확장하기 위해 수만 줄의 생성 규칙을 새로 작성해야 하거나, 언어가 진화하며 추가된 신규 기능을 제때 테스트하지 못하고, 사전에 정의된 언어 문법의 일부 하위 집합만 탐색하여 다양한 입력 공간을 커버하지 못하는 한계가 존재한다.
Core Idea
대규모 언어 모델을 퍼징의 입력 생성 및 변이 엔진으로 활용하는 Universal Fuzzing(범용 퍼징) 개념을 제안한다. 사용자가 제공한 원시 문서를 최적의 요약 프롬프트로 변환하는 자동 프롬프트 생성 기법과, 매 루프마다 이전 생성 결과물과 타깃 지침을 조합하여 프롬프트를 진화시키는 퍼징 루프를 구축함으로써 별도의 시스템 계측 없이도 유효하고 다양한 테스트 케이스를 끊임없이 생성한다.
Method
Fuzz4ALL은 정보의 정제와 압축을 담당하는 Distillation LLM(추론 능력이 뛰어난 대형 모델)과 실제 퍼징 입력을 빠르게 대량 생산하는 Generation LLM(비용 효율적인 소형 코드 모델)의 이원화 구조로 구동된다. 전체 아키텍처는 크게 두 단계로 나뉜다.
1. Autoprompting(자동 프롬프트 생성)
사용자가 제공한 설명서, 예제 코드, 명세 등의 원시 입력 데이터는 퍼징에 불필요한 군더더기가 많다. 이를 해결하기 위해 정제 모델을 통해 핵심 정보를 보존한 프롬프트 후보들을 자동 생성하고 평가한다.
-
프롬프트 추출: 정제 모델 에 사용자 입력 과 요약 지시문 을 전달하여 조건부 확률 기반으로 프롬프트를 샘플링한다.
-
그리디 및 고온 샘플링: 안정적인 후보 확보를 위해 온도를 0으로 설정한 그리디 샘플링을 먼저 수행한 뒤, 온도를 1로 높여 다양성을 확보한 후보군을 추가 수집한다.
-
검증 기반 점수화: 각 후보 프롬프트로 생성 모델 를 구동해 테스트 대상 시스템에서 오류 없이 통과하는 유효한 고유 코드 스니펫 의 개수를 측정하고, 이 점수가 가장 높은 최종 프롬프트 를 퍼징에 투입한다.
2. Fuzzing Loop (프롬프트 기반 퍼징 루프)
동일한 프롬프트로 반복 샘플링할 경우 출력이 고착화되는 LLM의 특성을 탈피하기 위해 프롬프트를 동적으로 변경하는 진화형 루프를 수행한다. 이전 세대에서 생성된 유효한 입력 코드 중 하나를 무작위 선택하여 예시로 결합하고, 아래의 세 가지 Generation Strategies 중 하나를 무작위로 인스트럭션에 붙여 새 코드를 유도한다.
generate-new: 제공된 명세를 바탕으로 완전히 새로운 프로그램을 작성하도록 요구한다.mutate-existing: 이전 생성 결과물의 구문이나 변수 타입을 변경하는 변이를 요구한다.semantic-equiv: 프로그램의 동작 의미는 유지하되 구조적 표현만 바꾸는 의미론적 등가 변이를 실행한다.
Results
C, C++, SMT2, Go, Java, Python 등 6개 언어를 사용하는 9개 주요 시스템을 대상으로 24시간 동안 퍼징 캠페인을 수행하여 전통적인 전용 퍼저들과 코드 커버리지 및 버그 발견 성능을 비교 검증했다.
| 테스트 대상 시스템 (SUT) | 비교 베이스라인 도구 | Fuzz4ALL 유효성 비율 | 최종 코드 커버리지 향상도 |
|---|---|---|---|
| GCC (C 컴파일러) | GRAYC, CSMITH | 37.26% | 베이스라인 대비 +18.8% |
| G++ (C++ 컴파일러) | YARPGEN | 40.74% | 베이스라인 대비 +26.5% |
| CVC5 (제약 솔버) | TYPEFUZZ | 47.63% | 베이스라인 대비 +24.9% |
| Go (런타임/툴체인) | GO-FUZZ | 23.02% | 베이스라인 대비 +13.7% |
| OpenJDK javac (자바) | HEPHAESTUS | 49.05% | 베이스라인 대비 +60.9% |
| Qiskit (양자 컴퓨팅) | MORPHQ | 24.90% | 베이스라인 대비 +75.6% |
- 커버리지 지속 상승: 전통적 퍼저들이 시간이 지남에 따라 커버리지 포화 상태에 도달하는 것과 달리, Fuzz4ALL은 루프가 지속되어도 프롬프트 진화 메커니즘 덕분에 캠페인 후반까지 새로운 코드 영역을 계속해서 발굴해 냈다.
- 실제 버그 발견: GCC, Clang, Z3, CVC5, OpenJDK, Qiskit 등 실제 널리 쓰이는 시스템에서 총 98개의 버그를 검출했으며, 이 중 64개는 개발자들로부터 기존에 알려지지 않은 유효한 신규 버그임이 공식 확인 및 수정되었다.
Key Figures
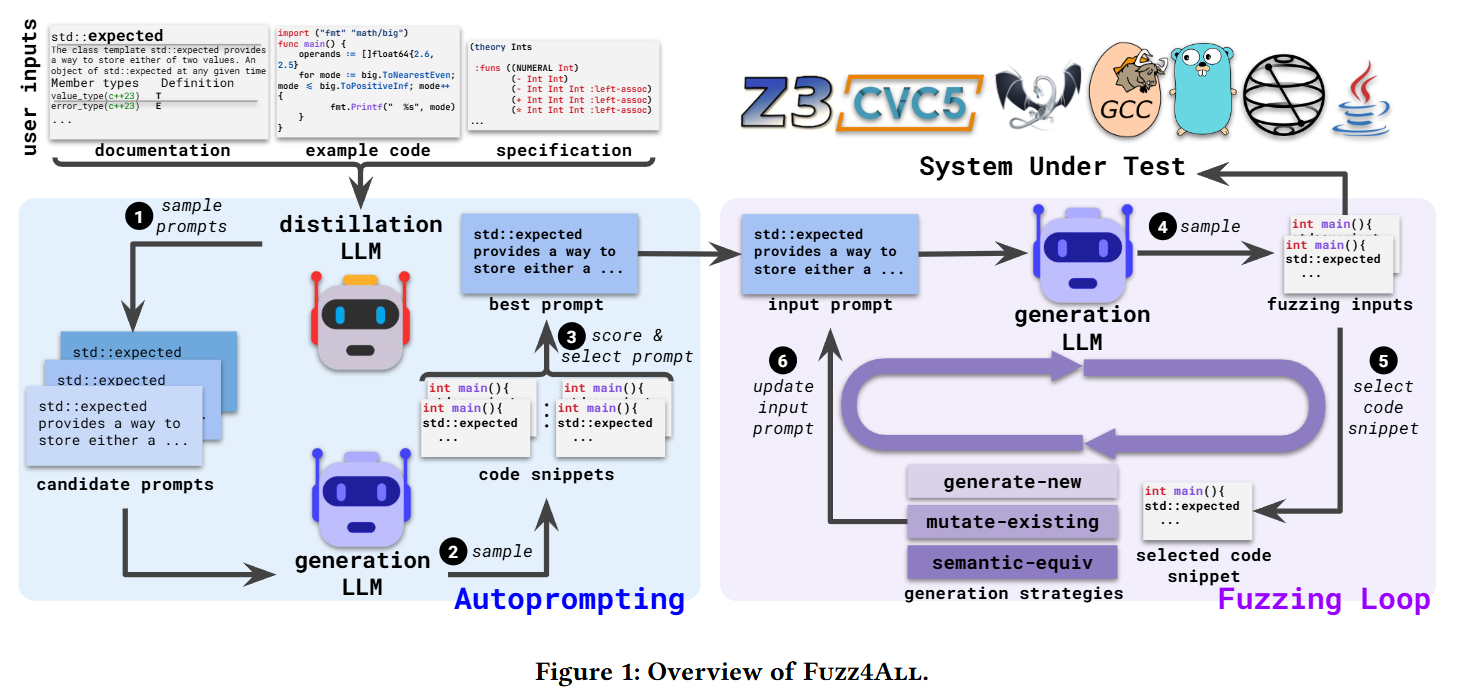
- Fig. 1: Fuzz4ALL의 전체 파이프라인 개요도. 왼편의 자동 프롬프트 생성 단계와 오른편의 프롬프트 진화 기반 퍼징 루프 단계가 유기적으로 연결되는 흐름을 시각화한다.
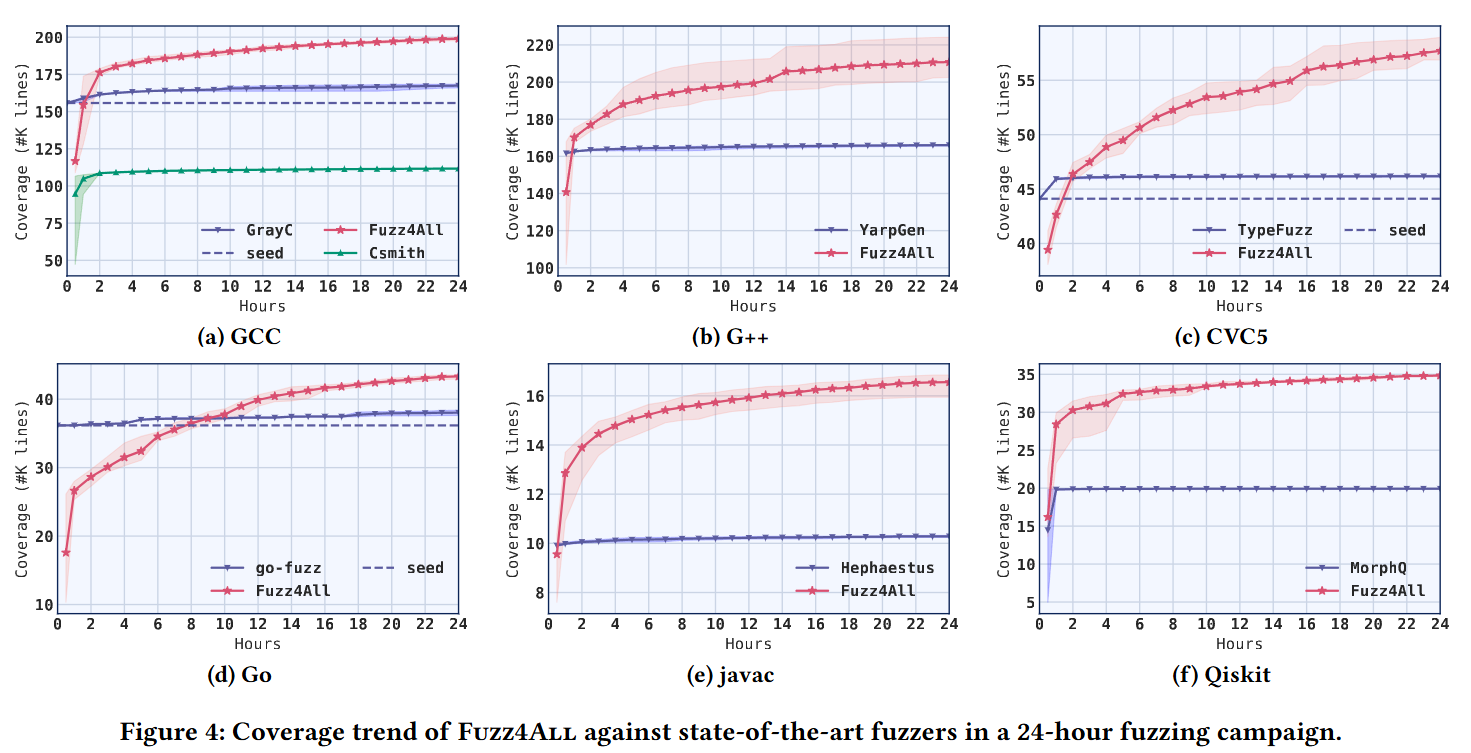
- Fig. 4: 24시간 누적 구동 조건에서 각 타깃별 코드 라인 커버리지의 시간 추이를 나타낸 그래프. 베이스라인 도구들과 비교해 Fuzz4ALL의 커버리지가 지속적으로 우상향하는 모습을 보여준다.
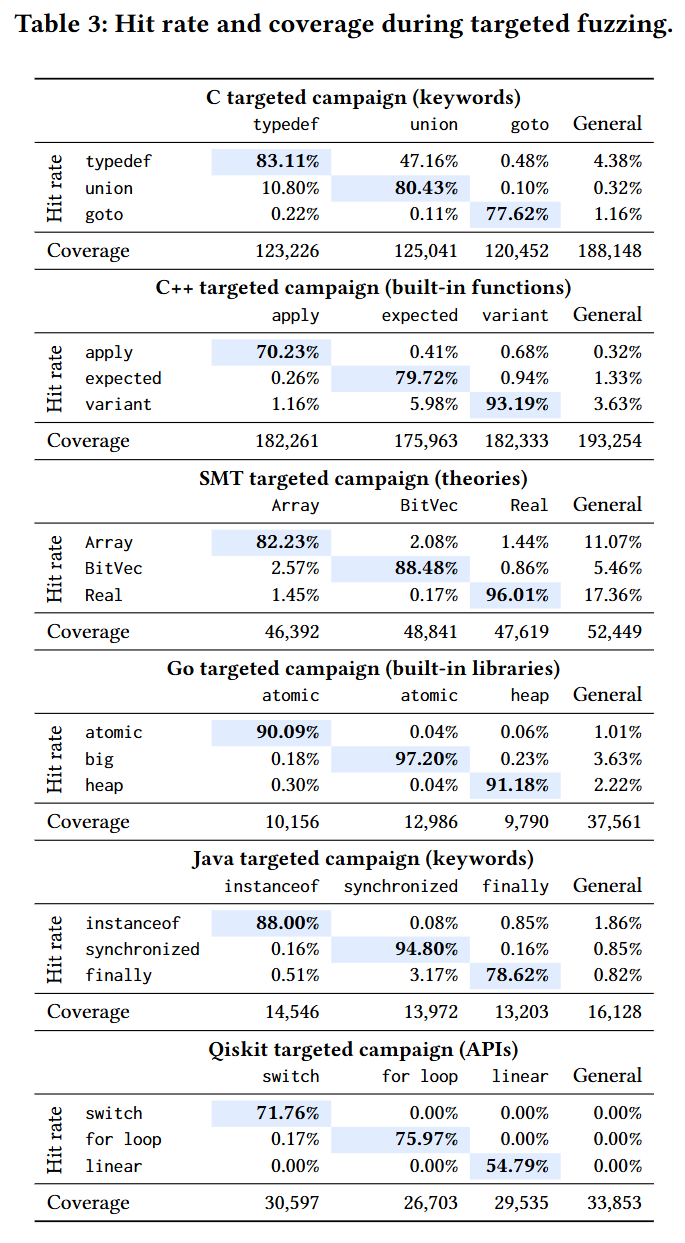
- Table 3: 특정 타깃 기능(C++23의
std::expected기능 등)의 문서만 주입했을 때 해당 API를 타깃팅하여 집중적으로 코드를 생성해 내는 표적 퍼징 성능 평가 표. 평균 83.0%의 높은 적중률을 입증한다.
Contribution vs Limitation
저자 주장
- 수많은 정형 언어와 플랫폼에 즉시 적용 가능한 최초의 LLM 기반 범용 퍼징 방법론 정립
- 원시 문서를 효율적인 퍼징 지침으로 변환해 주는 하이브리드 블랙박스 자동 프롬프트 정제 기술 개발
- 예제 문맥과 의미론적 변이 전략을 결합하여 생성 다각화를 유도하는 프롬프트 기반 테스팅 루프 설계
- 주요 오픈소스 컴파일러 및 솔버 엔진에서 수십 개의 미공개 핵심 결함을 잡아내어 실용성 검증
저자가 밝힌 한계
- GPU 인프라 병목: 입력 생성 시 LLM 추론 오버헤드가 발생하여 전통적인 바이트 변이형 퍼저 대비 테스트 케이스 생성 속도가 평균 43.0% 느리다.
- 낮은 문법 유효성: 문법 규칙을 강제하지 않는 확률적 생성 모델 특성상 베이스라인 도구에 비해 문법적으로 유효한 프로그램의 생성 비율 자체는 다소 낮다.
- LLM 환각 및 데이터 시프트: 정제 모델이 허위 명세를 요약해 내는 환각 현상이 발생할 수 있으며, 고정된 모델 엔드포인트를 오랜 기간 재사용할 경우 타깃 언어 사양과의 버전 불일치가 일어날 위험이 존재한다.
언어 모델 내부의 지식을 동적으로 인출하기 위해 프롬프트 변이 체계를 차용한 시도는 훌륭하나, 생성 속도 저하는 지속적인 대규모 회귀 테스트 환경에서 상당한 비용 부담으로 작용할 것이다. 깊은 코드 로직에 도달하기 전 구문 분석 단계에서 바로 거부되는 '유효하지 않은 코드'의 무의미한 반복 생성을 억제하기 위해, 구문 트리 제약 조건을 플러그인 형태로 결합하는 하이브리드 필터링 방식이 보완되어야 할 것으로 추정된다.
Quotes
- "This paper presents Fuzz4ALL, the first fuzzer that is universal in the sense that it can target many different input languages and many different features of these languages." (p.1)
- "The key idea behind Fuzz4ALL is to leverage large language models (LLMs) as an input generation and mutation engine..." (p.1)
- "By using an LLM as the generation engine, Fuzz4ALL is bottlenecked by GPU inference, leading to 43.0% fewer fuzzing inputs compared to traditional fuzzers." (p.8)
- "In spite of the lower validity rate and number of fuzzing inputs, Fuzz4ALL generates much more diverse programs compared to traditional fuzzing tools, as evidenced by the high coverage obtained (+36.8% average increase)." (p.8)
Idea Seeds
- 구문 유효성 가이드 퍼징: LLM이 코드를 생성하는 중간 토큰 단계에서 정적 분석기나 파서를 인터리빙하여 문법 오류가 감지되면 토큰을 마스킹하고 역추적하는 실시간 구문 교정 레이어 추가
- 강화학습 연계형 프롬프트 전략 최적화: 코드 커버리지 피드백 점수를 보상 함수로 삼아
mutate-existing이나semantic-equiv등의 하위 프롬프트 인스트럭션 조합 비율을 실시간으로 갱신하는 밴딧 아키텍처 도입
For My Writing
대규모 언어 모델을 소프트웨어 보안 및 품질 검증에 접목하려는 최근 연구 흐름 속에서, Xia 등은 특정 명세나 정형 문법을 하드코딩하지 않고도 다국어 소스코드와 컴파일러의 경계 결함을 탐색할 수 있는 최초의 범용 퍼저 Fuzz4ALL을 제시했다. 이 기법은 입력 생성 엔진과 정제 엔진을 분리하고 지속적인 프롬프트 컨텍스트 업데이트를 통해 생성의 다양성을 확보함으로써 언어의 급격한 진화와 사양 변경에 유연하게 대응해야 하는 최신 소프트웨어 테스팅 환경에 시사하는 바가 크다.
Open Questions
저자가 다루지 않은 것
- 생성된 무효 코드 중 단순 구문 에러를 넘어 타깃 컴파일러의 내부 예외 처리 로직이나 에러 복구 모듈의 결함을 유도해 내는 정밀한 '의도된 에러 코드 생성' 제어 방안은 논의되지 않았다.
Links
- 선행 연구: Csmith (Yang et al., 2011) — 전통적인 C 컴파일러 전용 문법 기반 퍼징 연구의 시초
- 선행 연구: TitanFuzz (Deng et al., 2023) — 특정 딥러닝 라이브러리를 표적으로 삼았던 초기 LLM 기반 테스팅 기법
- 관련 주제: 대규모 언어 모델 기반 프롬프트 엔지니어링 및 블랙박스 최적화 기법
References
- DOI: 10.1145/3597503.3639121
- arXiv: 2308.04748
- Code: github.com/fuzz4all/fuzz4all
- BibTeX key:
xia2024fuzz4all
@inproceedings{xia2024fuzz4all,
title = {FUZZ4ALL: Universal Fuzzing with Large Language Models},
author = {Xia, Chunqiu Steven and Paltenghi, Matteo and Tian, Jia Le and Pradel, Michael and Zhang, Lingming},
booktitle = {Proceedings of the 46th International Conference on Software Engineering (ICSE '24)},
pages = {1--13},
year = {2024},
publisher = {ACM}
}