Large Language Models as Commonsense Knowledge for Large-Scale Task Planning
Zirui Zhao, Wee Sun Lee, David Hsu (National University of Singapore) · 2023 · NeurIPS 2023
관련도: 상 · 읽은 이유: 내 논문에 인용하기 위해서, LLM을 하나의 설계도로 활용한 선행 연구를 분석 및 파악하기 위함이다.
LLM은 정답을 바로 내놓는 '해결사(Policy)'일 뿐만 아니라 세상이 어떻게 돌아가는지 아는 '설계도(World Model)'이기도 하다. 이 두 역할을 결합해 복잡한 미로(탐색 공간)에서 지도를 보며 유망한 길을 골라가는 것이 LLM-MCTS의 핵심이다.
One-liner
LLM의 상식적 지식을 세계 모델(World Model)과 행동 정책(Policy)으로 분리하여 Monte Carlo Tree Search (MCTS)에 통합함으로써, 복잡하고 낯선 가상 환경에서의 작업 계획 성능을 대폭 향상시켰다.
Problem
대규모 작업 계획(Large-scale task planning)은 기하급수적으로 거대한 탐색 공간을 가진다. 기존의 LLM 활용 방식은 LLM을 직접적인 정책(L-Policy)으로 사용하여 다음 행동을 쿼리하는데, 이는 훈련 데이터에 없는 낯설거나 복잡한 작업(novel, complex tasks)에서 일반화 능력이 급격히 떨어진다는 한계가 있다.
Core Idea
LLM이 가진 방대한 데이터를 기반으로 World Model (상식적 믿음)과 Policy (탐색 가이드)를 동시에 유도하여 MCTS 알고리즘에 결합한다. LLM 유도 세계 모델은 탐색을 위한 상식적 사전 믿음을 제공하고, LLM 유도 정책은 유망한 노드를 우선적으로 탐색하게 하는 휴리스틱 역할을 수행한다.
Method
논문은 LLM-MCTS 알고리즘을 제안하며, 이는 부분 관찰 마르코프 결정 과정 POMDP (Partially Observable Markov Decision Process, 튜플 ) 프레임워크를 따른다.
- L-Model (상식적 세계 모델): LLM을 이용해 물체 위치 등에 대한 초기 믿음 를 생성한다. 예를 들어 "사과는 어디에 있을까?"라는 질문에 LLM이 "냉장고 안" 혹은 "식탁 위"라고 답한 확률 분포를 사전 확률로 사용한다. 자연어 응답은 sentence-BERT 임베딩의 코사인 유사도를 통해 허용 가능한 객체 이름(canonical form)에 매핑된다.
- L-Policy (행동 휴리스틱): 현재 관찰과 행동 이력을 바탕으로 LLM을 번 샘플링하여 행동의 경험적 확률 분포 를 추정한다. 이는 MCTS의 PUCT (Predictor Upper Confidence Bound applied to Trees) 단계에서 행동 선택 가이드로 사용된다.
- MCTS Integration: 시뮬레이션 과정에서 LLM이 제안한 행동 정책을 활용해 탐색 효율을 높이고, 실제로 환경에서 얻은 관측치를 바탕으로 믿음을 업데이트한다.
행동 선택 수식은 다음과 같다 (Alg. 1, line 29).
여기서 는 LLM이 제안한 정책 분포이며, 탐색되지 않은 유망한 경로에 가중치를 부여한다.
Results
VirtualHome 시뮬레이션 플랫폼에서 평가했다. 학습용 10,000 전문가 궤적 중 200개를 few-shot 프롬프트 후보로 사용하고, 별도 생성한 800개의 객체 재배치 작업으로 평가했다 (성공 기준: 30스텝 이내 목표 배치 충족).
성공률 (%, mean ± s.e.) — 주요 컬럼 발췌
| 방법론 | Seen Simple | Seen NovelComp(2) | Seen NovelComp(3) | Unseen NovelComp(2) | Unseen NovelComp(3) |
|---|---|---|---|---|---|
| UCT (상식 없음) | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Finetuned GPT-2 policy | 81.3 | 30.9 | 2.3 | 12.8 | 1.1 |
| GPT-3.5 Policy (L-Policy) | 83.4 | 48.2 | 5.4 | 54.0 | 6.9 |
| GPT-3.5-MCTS (Ours) | 91.4 | 72.6 | 33.6 | 70.4 | 38.8 |
- Generalization: 학습 분포에서 벗어난 신규 조합 작업(NovelComp), 특히 3개 primary task가 합성된 경우에 L-Policy 대비 격차가 극적으로 벌어진다. 흥미롭게도 fine-tuning은 오히려 성능을 떨어뜨려(F2), in-context few-shot 학습이 generalization에 더 유리함을 시사한다.
- Novel Apartment: 학습 시 보지 못한 배치 분포의 아파트(Unseen Home)에서도 성능 순위가 유지된다.
- Ablation 성격의 비교: UCT(=세계 모델도 정책도 없음)는 완전 실패, L-Policy만(=휴리스틱 있고 탐색 없음)은 단순 작업에서만 작동 → 세계 모델과 휴리스틱 정책의 결합이 필수적임.
- MDL 원칙: 최소 기술 길이(Minimum Description Length) 원칙을 통해, 세계 모델의 설명 길이가 정책보다 훨씬 짧을 때(예: 대규모 곱셈, 다중 경유 여행 계획) 모델 기반 접근법이 일반화에 더 유리하다는 이론적 가이드를 제시했다.
Key Figures
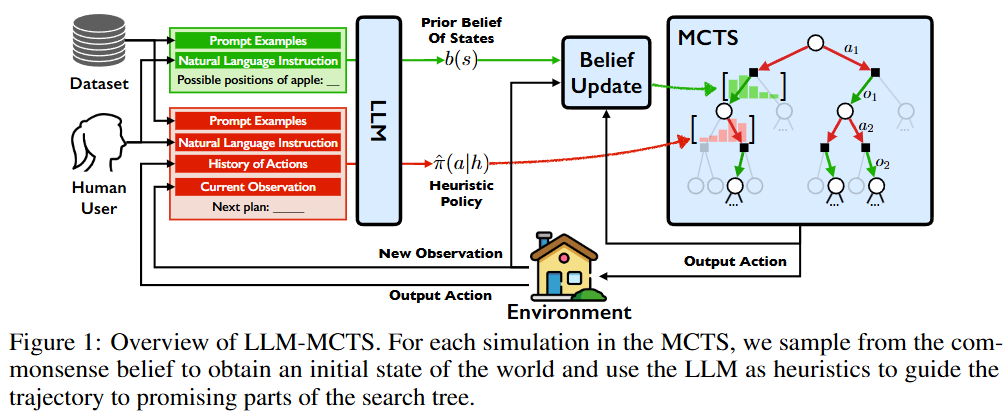
- Fig. 1: LLM이
Prior Belief와Heuristic Policy를 생성하여 MCTS 엔진에 주입하고, 환경과 상호작용하는 전체 시스템 아키텍처.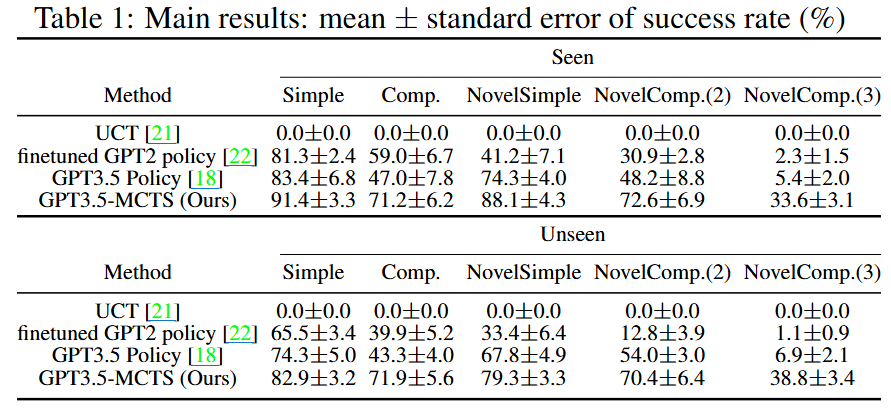
- Table 1: Seen/Unseen 아파트 × 단순/복합 작업 그리드로 구성된 성공률 비교표. 복잡도(NovelComp(3))가 높을수록 본 논문 방법론의 격차가 두드러짐.
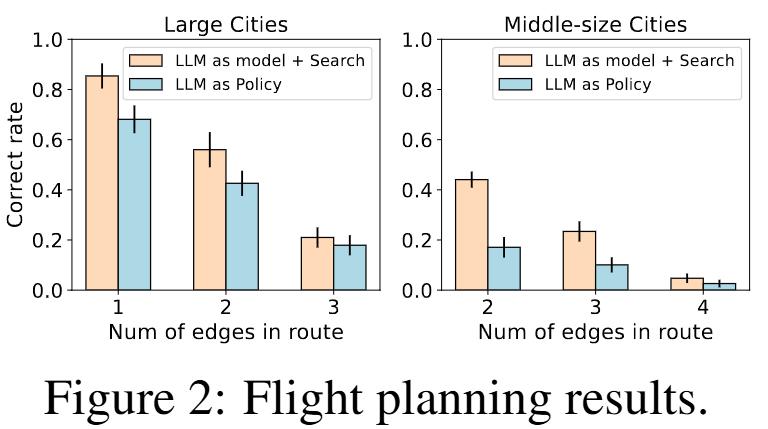
- Fig. 2: 다중 경유 여행 계획(multi-hop travel planning) 실험 결과. 경로가 길어질수록 정책 기반(L-Policy)보다 모델 기반(LLM as world model + search) 탐색이 훨씬 정확해짐을 보여 MDL 분석을 실증적으로 뒷받침.
Contribution vs Limitation
저자 주장
- LLM을 단순한 정책이 아닌 세계 모델로 활용하는 새로운 패러다임 제시.
- 대규모 탐색 공간에서 LLM 지식을 MCTS의 사전 확률 및 휴리스틱으로 변환하는 메커니즘 구축.
- MDL 원칙을 사용하여 모델 기반 vs 정책 기반 방식의 선택 기준에 대한 통찰 제공.
한계로 해석 가능한 지점
- Runtime Cost: 매 결정마다 번의 LLM 샘플링이 필요하여 실행 비용이 큼.
- Hallucination / Model 부정확성: F1 분석에서 L-Model 단독 성능이 낮은 원인 중 하나로 세계 모델의 부정확성이 제시됨.
- Translation 오류: 자유 형식 자연어를 시뮬레이터의 허용 가능한 행동/객체 이름으로 매핑할 때 cosine similarity 기반 매핑이 필요하며, 이 과정에서 오류가 발생할 수 있음.
LLM의 추론 비용(token cost)과 시간 지연이 실시간 로봇 제어에 적용하기에는 아직 매우 높다. 하지만 이 연구는 LLM의 지식을 '추론 엔진'이 아닌 '정보원'으로 격상시켰다는 점과, 신경망 기반의 직관(Policy)과 고전적 알고리즘의 논리(MCTS)를 결합하는 표준적 구조를 제시했다는 점에서 실제적 가치가 높다.
Quotes
"LLMs provide a commonsense model of the world in addition to a policy that acts on it." (p.1)
"if the description length of the world model is substantially smaller than that of the policy, using LLM as a world model for model-based planning is likely better than using LLM solely as a policy." (p.1)
"Simplicity is preferred, a well-known general principle in machine learning." (p.2)
Idea Seeds
- Hierarchical LLM-MCTS: 상위 수준의 작업 분해는 모델 기반으로, 하위 수준의 세밀한 동작 제어는 정책 기반으로 수행하는 계층 구조.
- Self-Correcting World Model: MCTS 탐색 중 얻은 실제 관측치를 바탕으로 LLM의 잘못된 상식(belief)을 실시간으로 교정(fine-tuning or RAG)하는 시스템.
- Efficiency Bottleneck: 작은 크기의 로컬 LLM(Llama-3 등)을 사용해 탐색 단계의 비용을 줄이면서도 대형 모델의 지식을 증류(distillation)하는 연구.
For My Writing
이 논문은 로보틱스나 AI 에이전트 설계에서 "왜 LLM을 정책으로만 쓰면 안 되는가"에 대한 논거로 활용하기 좋다. 특히 4절의 MDL(최소 기술 길이) 분석은 시스템 설계 시 모델 기반(Planning)과 정책 기반(End-to-End) 사이의 트레이드오프를 설명하는 강력한 이론적 도구가 된다. 복잡한 추론이 필요한 도메인에서 LLM을 단순 챗봇이 아닌 시스템의 한 모듈(World Model)로 정의할 때 이 논문을 주요 레퍼런스로 인용할 수 있다. 또한 fine-tuning이 generalization을 해치는 사례(Finetuned GPT-2 < GPT-3.5 few-shot)는 in-context learning의 장점을 설명할 때도 활용 가능하다.
Open Questions
이해하지 못한 것
- PUCT 수식에서 LLM 정책 분포 를 실제 확률값으로 정규화하는 과정에서, 저자들이 사용한 uniform mixing 하이퍼파라미터 가 결과에 미치는 민감도.
저자가 다루지 않은 것
- 환경의 물리적 제약이나 동적인 변화(다른 에이전트의 존재 등)가 있는 상황에서의 세계 모델 갱신 효율성.
- 다중 에이전트 협력 작업에서의 LLM-MCTS 확장 가능성.
- LLM 자체의 few-shot 프롬프트 구성(K=?, 예제 선택 방법)에 대한 민감도 분석.
Links
- 선행 연구: Monte Carlo Tree Search (Browne et al. 2012, Kocsis & Szepesvári 2006 UCT), VirtualHome (Puig et al.)
- 관련 주제: Tree of Thoughts (ToT), Chain of Thought (CoT), Neuro-symbolic AI, RAP (Hao et al. 2024)
References
- arXiv: 2305.14078
- OpenReview: FDeV7BOcob
- Project Page: llm-mcts.github.io
- Code: github.com/1989Ryan/llm-mcts
- BibTeX key:
zhao2023llmmcts
@inproceedings{zhao2023llmmcts,
title = {Large Language Models as Commonsense Knowledge for Large-Scale Task Planning},
author = {Zhao, Zirui and Lee, Wee Sun and Hsu, David},
booktitle = {Advances in Neural Information Processing Systems 36 (NeurIPS 2023)},
year = {2023}
}