Large Language Models for Software Engineering: Survey and Open Problems
Angela Fan, Mitya Lyubarskiy, Beliz Gokkaya, Shubho Sengupta, Mark Harman, Shin Yoo, Jie M. Zhang · 2023 · ICSE-FOSE 2023
관련도: 상 · 읽은 이유: 소프트웨어 공학 도메인에서 LLM을 결합한 최신 하이브리드 기법들의 현황과 발전 방향 파악
소프트웨어 공학은 execution이라는 자동화된 ground truth를 가지므로, 전통적인 소프트웨어 검증 기술을 LLM과 결합하는 하이브리드 접근법을 통해 할루시네이션을 통제하고 신뢰성을 극대화할 수 있다.
One-liner
소프트웨어 공학(SE) 전반에 걸친 대형 언어 모델(LLM)의 활용 동향과 한계를 분석하고, 전통적 SE 기법과 LLM을 결합하는 하이브리드 접근법의 필요성과 개방형 과제를 제시한다.
Problem
LLM은 코드 생성 등 다양한 소프트웨어 개발 활동에서 높은 성능을 보이지만, 할루시네이션(hallucination)으로 인해 그럴듯하지만 결함이 있는 산출물을 생성할 위험이 공존한다. 또한, 모델의 비결정성(non-determinism) 문제로 인해 일관된 성능 평가가 어려우며, 요구사항 공학 및 리팩터링과 같은 고수준의 아키텍처 설계 영역에 대한 연구는 구현이나 테스팅에 비해 상대적으로 미진한 상태이다.
Core Idea
소프트웨어 공학은 다른 언어 모델 적용 분야와 달리 소프트웨어 실행을 통해 자동화된 검증이 가능하다는 독보적인 장점을 지닌다. 따라서 정적 분석, 자동화된 테스트 데이터 생성, 검색 기법 등의 전통적인 SE 기술을 LLM과 융합하는 하이브리드 접근법을 통해 생성물의 신뢰성을 실시간으로 필터링하고 최적화해야 한다.
Method
논문은 소프트웨어 개발 활동과 연구 도메인을 기준으로 기존 문헌을 분류하고 프레임워크를 제안한다.
- Model Classification: SE 과제에 적용되는 LLM의 구조를 구글 BERT 등 Encoder-only, 메타 BART 등 Encoder-decoder, 오픈AI GPT 및 메타 LLaMA 등 Decoder-only 모델로 세분화하여 각 특성에 맞는 타깃 과제를 매핑한다.
- Automated Regression Oracle: 비기능적 최적화나 리팩터링과 같이 기존 기능의 보존이 필수적인 작업에서, 기존 시스템의 원래 동작 자체를 기준 오라클로 삼아 LLM의 할루시네이션 출력을 실시간으로 조율하고 검증하는 메커니즘을 정의한다.
- Generate-and-Test Approach: 자동 프로그램 수리(APR) 및 유전적 개선(GI) 연구에서 성숙한 기반을 다진 검증 프레임워크를 도입하여, LLM이 제시한 다수의 코드 후보군을 자동화된 테스트 세트를 통해 필터링하고 최적의 해를 검색하는 파이프라인을 강조한다.
Results
arXiv 메타데이터 분석 결과, 2019년 이후 LLM 기반 소프트웨어 공학 연구 논문은 급격히 증가하여 전체 컴퓨터 과학 분야 LLM 관련 논문 중 10% 이상을 차지할 만큼 주류 연구 분야로 부상하였다.
각 벤치마크 및 테스트 도메인별 세부 성과는 다음과 같다.
| 평가 모델 / 기법 | 타깃 벤치마크 | 주요 성과 및 지표 | 비교 대상 대비 성능 |
|---|---|---|---|
| Reflexion (GPT-4 기반) | HumanEval | Pass@1 정확도 90% 이상 달성 | GPT-4 단독 zero-shot (67%) 대비 대폭 향상 |
| CODAMOSA (CodeX + SBST) | 486개 벤치마크 | 테스트 커버리지 Stall 구간 탈출 및 고커버리지 달성 | 검색 기반 테스트 생성(SBST) 및 LLM 단독 모델 상회 |
| ChatFuzz (ChatGPT + AFL) | 12개 대상 프로그램 | 브랜치 커버리지 13% 향상 | 기존 그레이박스 퍼저 AFL 대비 우위 |
| EvalPlus 프레임워크 | HumanEval 정밀 검증 | 엄격한 테스트 입력 생성으로 Pass@k가 평균 15% 하락함을 증명 | 기존 불완전한 테스트 세트의 높은 위양성(False Positive) 판정 한계 폭로 |
Key Figures
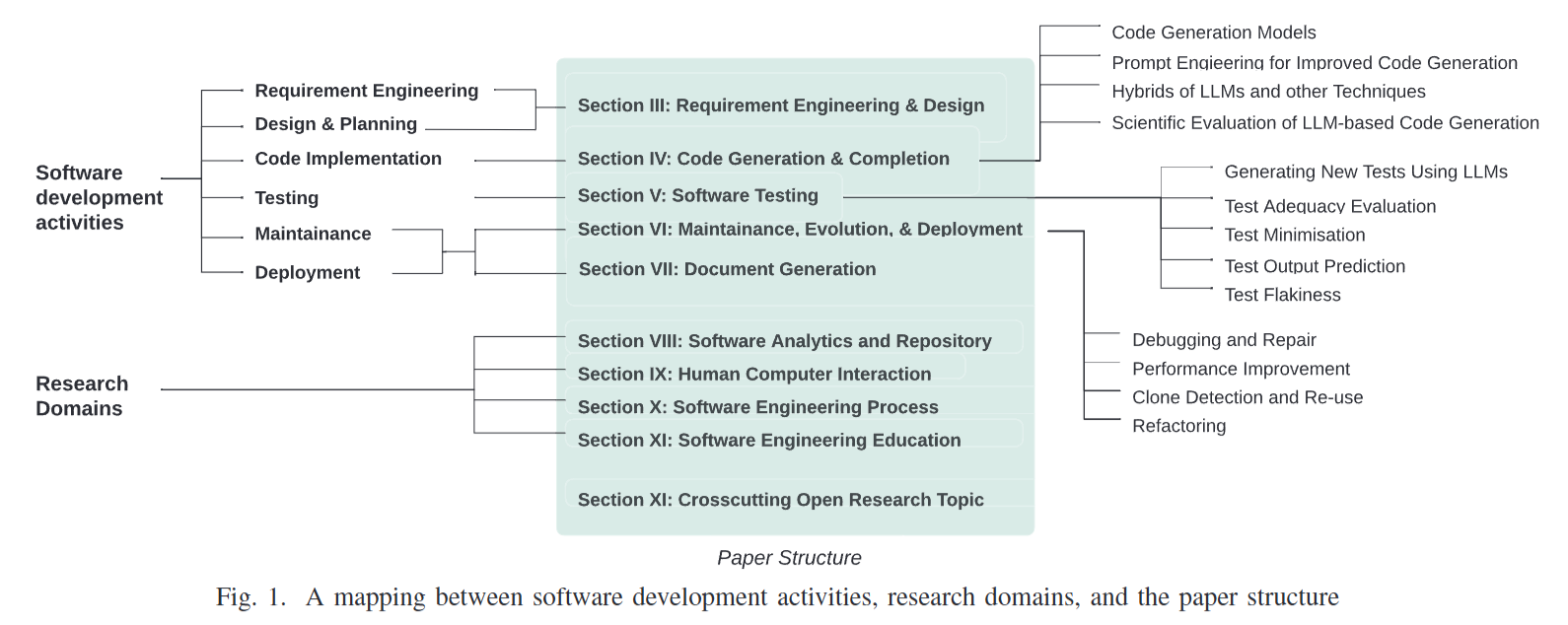
- Fig. 1: 요구사항 분석, 디자인, 코드 구현, 테스팅, 유지보수, 배포 등 소프트웨어 개발 생태계의 활동 영역과 본 논문의 절별 연구 도메인 구조 간의 유기적 매핑 관계를 도식화한다.
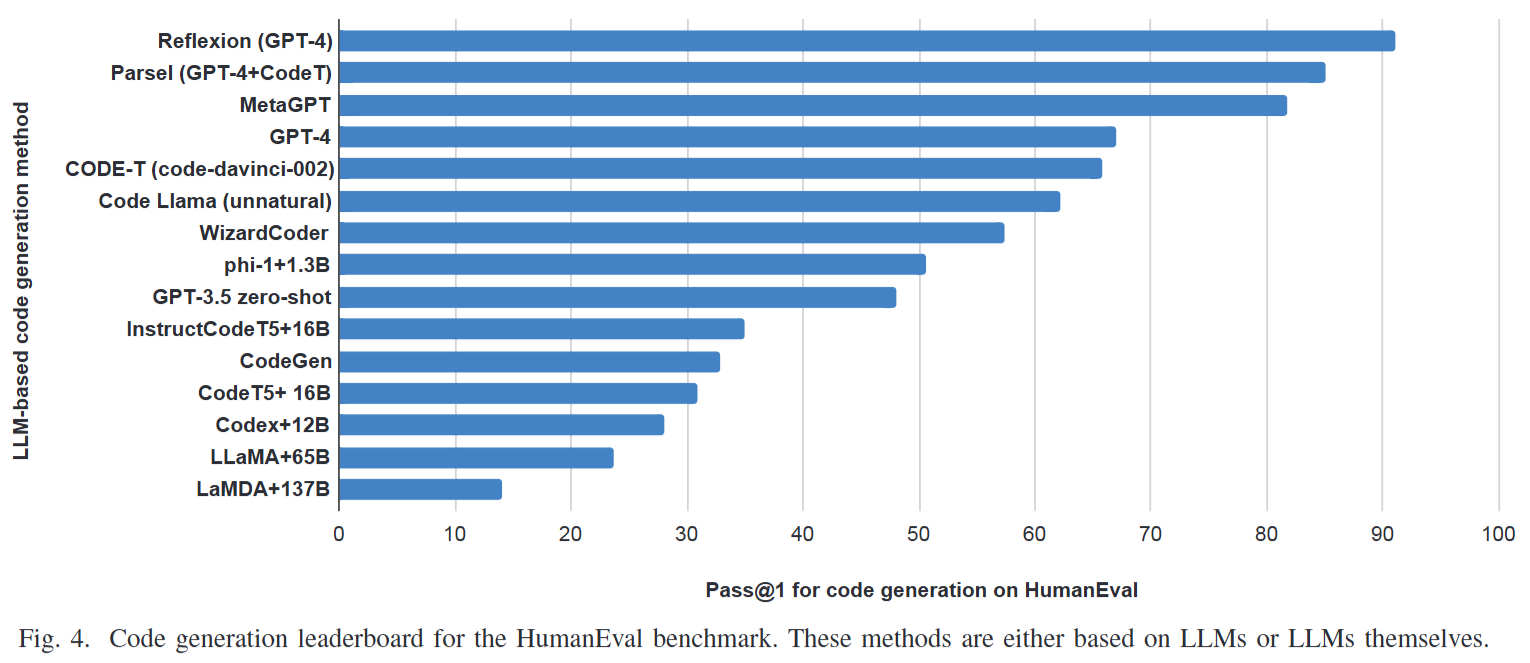
- Fig. 4: HumanEval 데이터셋 기준 코드 생성 리더보드를 보여주며, 단순 LLM 성능을 넘어 에이전트 워크플로우나 하이브리드 보정 기법이 결합될 때 정확도가 극대화됨을 실증한다.
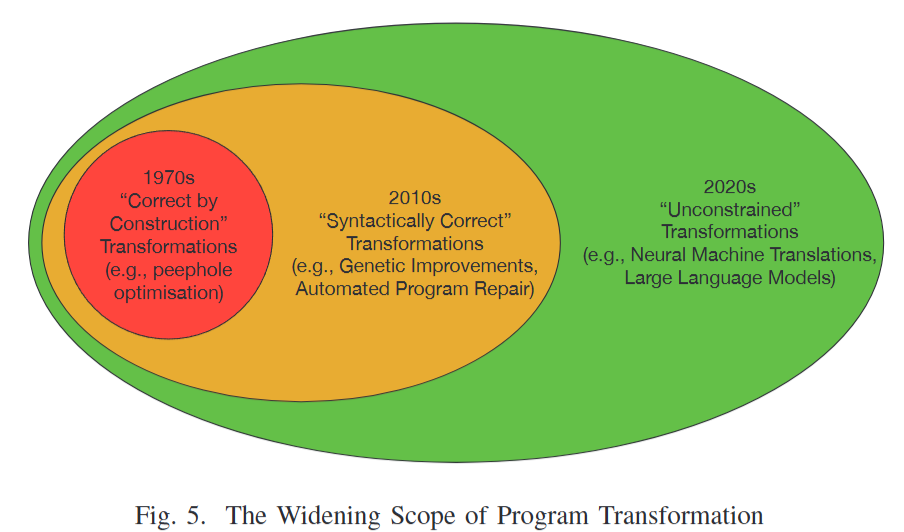
- Fig. 5: 1970년대의 정밀한 구조적 정합성 변환에서부터 2010년대의 구문적 타당성 변환, 그리고 2020년대 LLM 중심의 제약 없는 의미론적 주변부 변환으로 이행해 온 프로그램 변환의 역사적 확장 궤적을 설명한다.
Contribution vs Limitation
저자 주장
- 소프트웨어 공학 전반에 걸친 최신 LLM 적용 문헌에 대한 체계적인 스냅숏 제공한다.
- LLM의 한계를 방어하기 위해 전통적 SE 기법을 융합하는 하이브리드 방법론의 당위성을 정립한다.
- 설명 공학 및 할루시네이션의 역발상적 활용 등 미래 연구 아젠다를 상세히 구조화한다.
저자가 밝힌 한계
- 분야의 성장 속도가 매우 가팔라 완벽하게 포괄적인 문헌 수집을 보장하기 어려우며, 분석 데이터는 2023년 7월 27일 기준의 컷오프를 가진다.
- 추출된 문헌의 키워드 기반 필터링 쿼리는 본질적으로 근사치이므로 세부 수치 자체보다는 거시적 트렌드 위주로 해석해야 한다.
하이브리드 결합 방식의 필요성을 설득력 있게 제시하고 있으나, 실제 대규모 상용 클라우드나 지속적 통합(CI) 환경에 LLM 검증 오라클 시스템을 영구적으로 통합할 때 마주치는 컴퓨팅 비용, 토큰 제한 및 실시간 빌드 시간 병목 문제에 대한 구체적인 인프라 정량 분석은 제한적이다.
Quotes
"Unlike many other applications of LLMs, software engineers are typically blessed with automatable ground truth (software execution), against which most software engineering artefacts can be evaluated." (p.31)
"Already, more than 10% of all papers on LLMs are concerned with LLM-based Software Engineering." (p.33)
"The developer thus bears the responsibility to weed out any hallucinated LLM output before it leaks into the code base." (p.36)
"There is nothing correct about a flat battery" (p.44)
Idea Seeds
- 할루시네이션 기반 API 역설계: LLM이 존재하지 않는 가상의 API나 라이브러리 메서드를 할루시네이션으로 생성하는 경향을 역으로 이용해, 개발자가 미처 인지하지 못한 잠재적 인터페이스 개선 요구나 도메인 특화 언어(DSL) 설계를 자x동 도출하는 프레임워크 연구가 가능하다.
- 설명 공학과 코드 가독성의 상관관계: LLM이 생성한 복잡한 최적화 코드와 동반되는 코드 설명문의 구조가 개발자의 코드 인지 부하 및 디버깅 속도에 미치는 영향을 제어 실험을 통해 정량 측정하고, 가독성을 극대화하는 프롬프트 템플릿을 정형화한다.
For My Writing
이 논문은 AI 기반 소프트웨어 공학 도구의 신뢰성 검증 파이프라인 관련 논문을 작성할 때, 배경지식 및 관련 연구 섹션에서 핵심적인 이론적 토대로 활용할 수 있다. 특히 LLM의 할루시네이션 취약점을 지적하면서도, 소프트웨어 도메인 특유의 '실행 가능한 지상 실사(executable ground truth)'라는 속성을 방어 기제로 제시하는 논증 구조를 인용하여 본 연구가 제안하는 자동화 필터링 메커니즘의 독창성과 당위성을 부각하는 전개에 적합하다.
Open Questions
이해하지 못한 것
- 모델의 비결정성이 지닌 리스크를 파라미터 제어(예: 온도 파라미터 조정)와 통계적 추론 검정을 결합하여 구체적으로 어떤 방식으로 수리적 최적화를 달성할 수 있는지에 대한 세부 공식화 과정이 명확히 기술되지 않았다.
저자가 다루지 않은 것
- 상용 LLM을 기업 코드베이스에 적용할 때 발생하는 소스코드 저작권 침해, 오픈소스 라이선스 오염 및 데이터 프라이버시 유출과 같은 법적·윤리적 거버넌스 문제에 대한 실무적 해결책이 누락되어 있다.
Links
- 선행 연구: Vaswani et al. (2017) Transformer 아키텍처 제시, Chen et al. (2021) CodeX 및 HumanEval 자산 구축 연구
- 관련 주제: Search Based Software Engineering (SBSE), Genetic Improvement (GI), Automated Program Repair (APR)
References
- DOI: 10.1109/ICSE-FOSE59343.2023.00008
- arXiv: 2310.03533
- Code: 명시되지 않음
- BibTeX key:
fan2023llmforse
@inproceedings{fan2023llmforse,
title = {Large Language Models for Software Engineering: Survey and Open Problems},
author = {Fan, Angela and Gokkaya, Beliz and Harman, Mark and Lyubarskiy, Mitya and Sengupta, Shubho and Yoo, Shin and Zhang, Jie M.},
booktitle = {Proceedings of the 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE)},
pages = {31--53},
year = {2023},
publisher = {IEEE},
doi = {10.1109/ICSE-FoSE59343.2023.00008},
note = {arXiv preprint arXiv:2310.03533}
}